(notas para una entrevista de Documentos TV.)
¿Cuál es la utilidad de Websays?
Websays permite que las instituciones y las empresas entiendan qué opinan las redes sociales y la Web en general.
Existen más de 200M de blogs en el mundo, así como miles de páginas de “reviews”, con millones de comentarios sobre restaurantes, hoteles y todo tipo de productos. Cada minuto que pasa se publican más de 30M de mensajes en Facebook y más de 300,000 en Twitter. Y una gran parte de esas conversaciones son públicas. Se trata de mensajes que los particulares dirigen a empresas, instituciones o al público en general. Todo ello constituye una valiosísima fuente de información sin precedentes: información sobre nuestras preocupaciones, sobre nuestras intenciones, sobre nuestras emociones.
El problema radica en que es tal la cantidad de conversaciones y de opiniones en la Web que necesitamos una tecnología punta para captar y analizar esa masa de información.
Y no es tarea fácil. En primer lugar hay que rastrear millones de páginas web, noticias online, blogs, forums y redes sociales, en tiempo real. Después, se debe filtrar la información para retener sólo la parte que nos interese, acerca de un tema, una marca, un individuo específico. Y ello resulta extremadamente difícil porque el lenguaje humano resulta muy ambiguo para los ordenadores.
Lo veremos claro con un ejemplo. Si quisiéramos saber qué opina la gente sobre la marca de ropa “Mango”, tendríamos que eliminar todas las conversaciones sobre la fruta –el mango- todas las menciones de restaurantes y bares que se llamen así…
Una vez se han filtrado adecuadamente las conversaciones, comienza el trabajo más difícil: el análisis que permita convertir los miles de conversaciones en unos pocos indicadores, tendencias, rankings… en definitiva la elaboración de un resumen de la información y la extracción de conclusiones.
Estas tareas deben realizarse miles de veces por día (en tiempo real), analizando millones de mensajes. Y, dada la enorme cantidad de conversaciones y la necesidad de conseguir datos inmediatos, es necesario que esa tarea se realice de un modo automático, mediante algoritmos1 distribuidos en muchos ordenadores (las famosas “granjas de ordenadores” que soportan “la nube”).
Sin embargo, la tarea es tan difícil que los algoritmos de que disponemos hoy en día no son capaces realizarla. A día de hoy no existe un algoritmo capaz de entender nuestras opiniones escritas y resumirlas fehacientemente. De ahí que utilicemos un equipo de analistas (humanos) que están continuamente mirando los datos y corrigiendo los errores de los algoritmos. Y a su vez utilizamos técnicas de inteligencia artificial para que los algoritmos aprendan de sus propios errores, y no los repitan.
¿ Cómo se pueden medir las palabras, cómo se puede medir el lenguaje?
Cuando alguien analiza cientos de opiniones escritas sobre un tema determinado –por ejemplo leyendo una consulta abierta, leyendo tweets o comentarios de una noticia online-, esa persona puede hacer un resumen de lo que ha leído y explicar los aspectos más importantes de lo leído. Puede indicar, por ejemplo, si las opiniones son más bien positivas, si se trata de quejas y cuál es el objeto principal de la queja, cuáles son los temas que interesan o preocupan más, quiénes son los líderes de opinión, etc.
Un algoritmo básico para analizar el sentimiento (o la polaridad) de un mensaje sería, por ejemplo, tener una lista de palabras positivas y palabras negativas en el contexto de conversación. Por ejemplo, “fría” estaría en la lista negativa (para captar frases como “la pizza estaba fría”) y “estupenda” estaría en la lista positiva (para captar frases como “la pizza era estupenda”). Pero este algoritmo tiene muchos problemas y falla en muchas ocasiones. Por ejemplo no sabe tratar las negaciones (“no está sucio”), y más importante: no es capaz de tener en cuenta el contexto (“una pizza fría” es negativo, pero una “cerveza fría” es positivo neutro). Tendríamos que añadir millones de términos, reglas y excepciones a nuestro algoritmo para que empezara a dar resultados fehacientes. Hacer esto para tratar cada caso, cada cliente, simplemente no es posible.
La solución es utilizar técnicas de Inteligencia Artificial (en particular las técnicas del Aprendizaje Automático o Machine Learning) para que el propio programa analice miles de ejemplos y errores y deduzca sus propias listas de términos, reglas y excepciones. Cuantos más datos etiquetados y corregidos tenemos, mejor será el resultado final de los algoritmos.
¿Encuestas –las de toda la vida- o conversaciones en la red? ¿Qué tiene más valor?
No hay duda alguna de que las encuestas son una herramienta fundamental para entender la opinión pública. Hasta hace poco, además, eran la única manera de conseguir datos cuantitativos sobre la opinión, tanto en campañas políticas como en
estudios de marketing. Pero la realidad es que las encuestas están a menudo equivocadas 2, porque realizar una encuesta presenta en la práctica muchos problemas:
- ¿cómo elegir las preguntas?
- ¿cómo conseguir una muestra representativa de la población, aun coste económico asumible?
- ¿cómo conseguir que los encuestados digan lo que en realidad piensan?
- ¿cómo reducir las respuestas a tres o cuatro posibilidades?, o, por en contrario, ¿cómo analizar miles de respuestas libres?
Las redes sociales nos brindan una alternativa a las encuestas tradicionales. Nos brindan la oportunidad de escuchar lo que la gente quiere compartir, sin necesidad de forzar las preguntas. Tenemos también la posibilidad de ser activos: lanzar muchos mensajes al público y comprobar luego cuáles tienen mayor interés para ciertas audiencias.
Websays ha realizado múltiples experimentos de predicción de votos en los que demostramos que algunos indicadores de impacto en las redes tienen mayor capacidad de predicción de voto que muchas encuestas, incluidas en algunos casos las encuestas a pie de urna. El último caso fue el estudio que hicimos del referendum inglés del 2016 (Brexit), en el que Websays junto con el consorcio SENSEI de investigadores europeos predijo que el “no” al “sí”, contrario a lo que predecían todas las encuestas.
¿Un dato tiene valor por sí mismo?
Cada datos es diferente. De los datos que analizamos en Websays, que son
opiniones emitidas en la Web, un solo dato no tiene valor por sí mismo; el valor se obtiene cuando se cotejan grandes cantidades de datos.
¿Cuánto valen los datos en el mercado?
Naturalmente, depende. Depende de cada dato, de su valor intrínseco. De hecho se forman cadenas de procesado de datos, algo así como ocurre con las materias primas que son re-procesadas, re-combinadas y re-comercializadas muchas veces hasta que llegan al cliente final en forma de producto. Websays, por ejemplo, gasta una parte de su presupuesto en la recolección y compra de datos públicos, para luego filtrarlos, analizarlos y re-venderlos.
Nos encontramos en una fase muy inicial del mercado de datos de ese tipo y por ello resulta muy difícil estimar cuál pueda llegar a ser el valor total de ese mercado. En estos momentos el sector que utiliza principalmente ese mercado de datos es el del Marketing. Sin embargo, creemos que en los próximos años otros sectores -banca, salud, turismo- serán mucho más activos. En realidad resulta difícil imaginar que a medio plazo aún existan sectores que puedan prescindir del mercado de datos de opinión.
¿Qué datos deben ser abiertos o cerrados, públicos o privados? ¿Cómo responder a la preocupación social sobre el control de datos?
Se trata de preguntas muy complejas, susceptibles de muchas
interpretaciones y repercusiones, y, claro está, a esas preguntas no se puede responder de manera simple. Y, además, la tecnología de análisis de datos avanza con tal rapidez, que resulta prematuro intentar zanjar la cuestión. ¡Cuando llegamos a una respuesta adecuada, cambian las preguntas!
En el campo de las redes sociales está claro que nos encontramos en un periodo muy temprano, en un periodo de experimentación, en el que vamos descubriendo las posibilidades que ofrecen las nuevas tecnologías para la comunicación, la organización, el marketing, la política, las relaciones amorosas y absolutamente todos los aspectos de la vida social en general. Somos algo así como un niño en una tienda de juguetes, que quiere probarlo todo y que pasa de un juguete a otro a gran velocidad. Sin embargo, el poder de cambio de estas nuevas tecnologías es tal que en nuestras propias experimentaciones estamos consiguiendo muchos resultados que hasta hace poco eran impensables -tanto positivos como negativos- desde cambios de gobierno a cyber-bulling.
En esta situación, cuando algo va mal nos volvemos, indignados, hacia las empresas de Internet (Facebook, Twitter, Instagram, y tantas otras que están por llegar) considerándolas como una especie de bien común diseñado para servirnos. Por el contrario, hay que ser conscientes que Internet crece gracias a empresas tremendamente innovadoras que nos dotan de nuevos medios de expresión y de comunicación, pero que son empresas privadas, oportunistas, carísimas, y en busca de grandes beneficios.
Un ejemplo puede ser útil. En cualquier cartel electoral de España de los últimos años observamos tres elementos: un slogan, una foto de un candidato, y un hash de Twitter! Cada cartel de cada partido de cada calle de España es una invitación a comunicar por Twitter (o Instagram, o Facebook). Con ello, se consigue un aspecto positivo enorme: una capacidad de comunicación y debate sin precedentes. Pero no hay que olvidar que Twitter no es un bien común, ni mucho menos; es una empresa americana que cotiza en bolsa en los Estados Unidos y que tiene todo su derecho en hacer lo que le plazca con las opiniones que voluntariamente le entregamos.
Si de verdad creemos que esa comunicación directa por red tipo Twitter o Whatsapp es fundamental para nuestra democracia, tendríamos que tomárnoslo más en serio y deberíamos dotarnos de las herramientas de control adecuadas.
¿Qué valor tiene un algoritmo, hoy en día?
Si un algoritmo permite aumentar considerablemente las ventas de un producto, o reducir de un modo considerable los costes de una empresa, se le puede dar un valor comercial que puede llegar a billones de euros. Si un algoritmo detecta un cáncer terminal un año antes de que pueda hacerlo el médico, el algoritmo tiene un gran valor social o de salud pública. Si un algoritmo nos permite entender mejor la opinión del público, de los ciudadanos, sobre un acontecimiento político, tiene un gran valor social o político.
Como con todos los otros productos y servicios, somos los seres humanos quienes decidimos el valor de los algoritmos en función de lo que nos permiten hacer.
¿Los algoritmos sirven para todo?
Los algoritmos son recetas lógico-matemáticas y, por lo tanto, pueden resolver sólo aquellos problemas cuya solución sea reducible a un problema lógico-matemático.
Lo que ocurre es que, en estos últimos años, la cantidad de problemas que se pueden resolver con algoritmos ha crecido mucho y muy rápido, y se hace difícil saber dónde está la frontera. Actividades como conducir un coche, pasar un examen de medicina o analizar una situación política estaban, hasta hace poco, fuera de las capacidades de los algoritmos.
¿Puede equivocarse un algoritmo que funciona de forma autónoma?
¡Claro que sí! Se equivocan continuamente. Cuanto más difícil es el problema y menos son los datos disponibles, más se equivocan.
Una parte muy importante de la teoría del aprendizaje automático es cómo medir de manera eficaz la equivocación de un algoritmo, para así intentar reducirla.
¿Un algoritmo tiene ideología?
No creo que términos tales como ideología, intención, personalidad o creencia se puedan aplicar a un algoritmo. Todas esas palabras pierden su significado normal si intentamos aplicarlas a las máquinas actuales. Tal vez en el futuro, con máquinas o algoritmos muchísimo más complejos, se pueda formular esta pregunta. Hoy por hoy, la respuesta clara es que no.
Pero los algoritmos puedes estar “sesgados” en sus concepción y sus conclusiones. Por ejemplo, si creo un algoritmo que analiza la opinión que hay sobre un tema a partir de sólo los primeros 100 resultados en un buscador de Google, entonces estará sesgado a estos resultados e ignorará los miles de otros resultados. Si estos resultados representan además sólo una ideología, entonces los resultados del algoritmo estarán sesgados por esta ideología. Pero de ahí a decir que el algoritmo tiene una ideología…
¿Qué decisiones no deben tomarse en base a algoritmos?
No creo que exista una respuesta simple a esta pregunta. Cada caso es diferente. Los algoritmos son herramientas, y cuando un ser humano decide usar una herramienta, por la razón que sea, la responsabilidad final es del humano.
Habrá casos en los que los seres humanos podremos decidir que es mejor dejar las decisiones a un algoritmo, y habrá otros casos en que no.
¿Qué papel juega la ética en todo este campo, incluyendo “machine learning”, IoT, Inteligencia Artificial?
No soy un experto en ética. Es obvio que toda nueva tecnología puede utilizarse con fines éticos, o todo lo contrario. En Websays intentamos centrarnos en el uso de la tecnología con fines acordes con nuestra Ética. Las tecnologías que desarrollamos en Websays tiene un enorme potencial para aprender de la opinión de la gente y para mejorar procesos tanto políticos como comerciales. Por primera vez podemos incluir la opinión real de la gente directamente en un proceso de decisión. Creo que ahí se encuentra un tremendo poder positivo
- Utilizo la palabra algoritmo porque está poniéndose de moda y es bonita; se puede considerar un sinónimo de palabras como programa informático, receta detallada, o fórmula lógica-matemática. ↩
- Escribo esta frase el día de la victoria de Trump… la caída de las bolsas internacionales esta mañana es un claro indicador de 1) nuestra confianza en las encuestas, y 2) su escasa exactitud. ↩
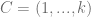 con tamaños
con tamaños 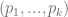 , y obtenemos las precisiones
, y obtenemos las precisiones 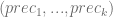 , y las coberturas
, y las coberturas 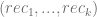 , entonces tenemos:
, entonces tenemos: